Least Recently Used (LRU) cache. We can describe this data structure using the following operations:
int get(int key)Return the value of the key if the key exists, otherwise return -1.void put(int key, int value)Update the value of the key if the key exists. Otherwise, add the key-value pair to the cache. If the number of keys exceeds the capacity from this operation, evict the least recently used key.
The functions get and put must each run in O(1) average time complexity.
If you want use it in Java, then standard library have LinkedHashMap for you!
public class LRUCache<K, V> extends LinkedHashMap<K, V>{
private final int capacity;
public LRUCache(int capacity){
super(capacity,0.75F,true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> entry) {
return size() > capacity;
}
}
But how is it work? I faced that question, when I was solving problems on leetcode. I found the following solution.
We need two data structures:
- Queue. It’s a simple linked list with small prioritization algorithm.
- HashMap. It’s a index on nodes in queue.
Scheme of cache:
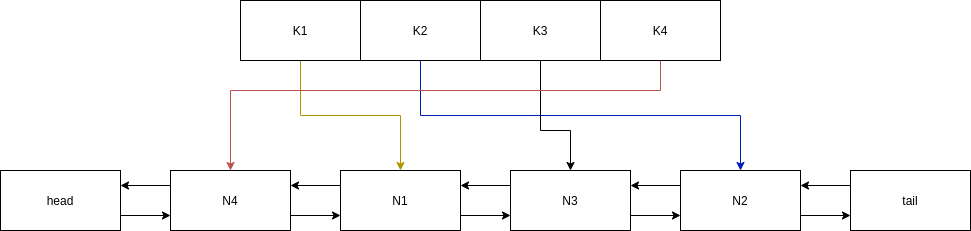
Method get is realized the next steps:
- Find key in HashMap.
- If map contains key, replace node on head in queue and return value
- If map doesn’t contain key, return null.
Method put is realized the next steps:
- Use
getfor finding key. - If
getreturn node, then update value - If cache doesn’t contain key, add a new node to the head of queue and remove node from the tail (if nessesary).
public class LRUCache<Key, Value> {
private Map<Key, Node> cache; // HashMap
// pointers on list
private Node head;
private Node tail;
// ---------------
private int cacheSize = 0;
private int capacity;
public LRUCache(int capacity) {
cache = new HashMap<>(capacity);
this.capacity = capacity;
head = new Node(null, null); // (1)
tail = new Node(null, null);
head.next = tail;
tail.prev = head;
}
public Value get(Key key) {
Node node = getNode(key);
if (node == null) {
return null;
}
return node.value;
}
public void put(Key key, Value value) {
Node node = getNode(key);
if (node == null) {
Node newNode = new Node(key, value);
if (cacheSize == capacity) {
Node remNode = tail.prev;
removeNode(remNode);
cache.remove(remNode.key);
} else {
cacheSize++;
}
addHead(newNode);
cache.put(key, newNode);
} else {
node.value = value;
}
}
private Node getNode(Key key) {
Node node = cache.get(key);
if (node == null) {
return null;
}
if (node == head.next) { // first node
return node;
}
removeNode(node);
addHead(node);
return node;
}
// this method doesn't remove, really. It only change pointers in adjoining nodes.
private void removeNode(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void addHead(Node node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
private class Node {
private Node prev;
private Node next;
private Key key;
private Value value;
public Node(Key key, Value value) {
this.value = value;
this.key = key;
}
}
}
(1) I use dummy values for avoiding corner cases: if (tail == null), if (head == null) or if (head == tail).
Disadvantages
This cache has one HUGE problem: if we add a lot of new item (more then cache size) and don’t read in this time (adding items in cycle), then all old items will be removed. LRU cache is like bubble sort - very simple, but not efficient.
Also you can find this code or code for other algorithms in this repo: https://github.com/Marbok/Algorithms_and_data_structures