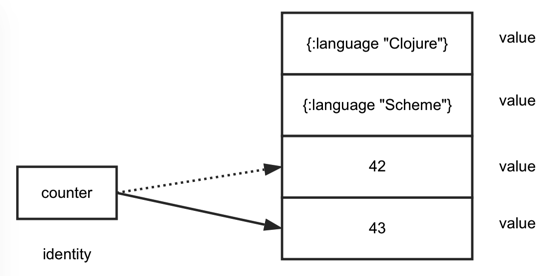
Identity/Value Separation
In Clojure, values are immutable. They never change. For example, a number is a value. A map {:language “Clojure”} is a value. A vector with 3 elements is a value.
When you attempt to modify a value (a data structure), a new value is produced instead. These are known as persistent data structures (the word “persistent” has nothing to do with storing data on disk).
An identity is a named entity (e.g., a list of active chat group members or a counter) that changes over time and at any given moment references a value. For example, the current value of a counter may be 42. After incrementing it, the value is 43 but it is still the same counter - the same identity. This is different from, say, Java or Ruby, where variables serve as identities that (typically) point to a mutable value and which are modified in place.
 Identities in Clojure can be of several types, known as reference types.
Identities in Clojure can be of several types, known as reference types.
Clojure Reference Types
Overview
In Clojure’s world view, concurrent operations can be roughly classified as coordinated or uncoordinated or isolated, and synchronous or asynchronous. Different reference types in Clojure have their own concurrency semantics and cover different kind of operations:
| Type of modification | Synchronous | Asynchronous |
|---|---|---|
| Coordinated | refs | - |
| Uncoordinated | atoms | agents |
| Isolated | vars | - |
Atoms
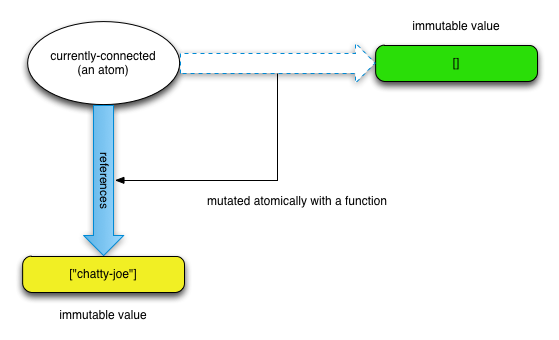
Atoms are references that change atomically (changes become immediately visible to all threads, changes are guaranteed to be synchronized by the JVM). If you come from a Java background, atoms are basically atomic references from java.util.concurrent with a functional twist to them. Atoms are identities that implement synchronous, uncoordinated, atomic updates.
To create an atom, use the clojure.core/atom function. Its argument will serve as the atom’s initial value:
(def currently-connected (atom []))
The line above makes the atom currently-connected an empty vector. To access an atom’s value, use clojure.core/deref or the @atom reader form:
(def currently-connected (atom []))
@currently-connected
;; -> []
(deref currently-connected)
;; -> []
currently-connected
;; -> #<Atom@614b6b5d: []>
As the returned values demonstrate, the atom itself is a reference. To access its current value, you dereference it.
To mutate an atom, we can use clojure.core/swap!.
swap! takes an atom, a function and optionally some other args, swaps the current value of the atom to be the return value of calling the function with the current value of the atom and the args:
(swap! currently-connected conj "chatty-joe")
;; -> ["chatty-joe"]
currently-connected
;; -> #<Atom@614b6b5d: ["chatty-joe"]>
@currently-connected
;; -> ["chatty-joe"]
Occasionally you will need to mutate the value of an atom the same way you would with atomic references in Java: by setting them to a specific value. This is what clojure.core/reset! does. It takes an atom and the new value:
@currently-connected
;; -> ["chatty-joe"]
(reset! currently-connected [])
;; -> []
@currently-connected
;; -> []
reset! may be useful in test suites to reset an atom’s state between test executions, but it should be used sparingly in your implementation code. Consider using swap! first.
Atoms is the most commonly used concurrent feature in Clojure. It covers many cases and lets developers avoid explicit locking. Atoms cover a lot of use cases and are very fast. It’s fair to say that when you need uncoordinated reference types (e.g., not Software Transactional Memory), the rule of thumb is, “start with an atom, then see”.
It is not uncommon to initialize an atom in a local and then return it from the function and share a piece of state with other functions and/or threads.
Agents
Agents are references that are updated asynchronously: updates happen at a later, unknown point in time, in a thread pool. Agents are identities that implement uncoordinated, asynchronous updates.
A small but useful example of using an agent is as a counter. For example, suppose we want to track how often page downloads in a Web crawler respond with 40x and 50x status codes. The simplest version can look like this:
(def errors-counter (agent 0))
;; -> #'user/errors-counter
errors-counter
;; -> #<Agent@6a6287b2: 0>
@errors-counter
;; -> 0
One can immediately make several observations: just like atoms, agents are references. To get the current value of an agent, we need to dereference it using clojure.core/deref or the @agent reader macro.
To mutate an agent, we use clojure.core/send and clojure.core/send-off:
@errors-counter
;; -> 0
(send errors-counter inc)
;; -> #<Agent@6a6287b2: 0>
@errors-counter
;; -> 1
;; 10 is an additional parameter. The + function will be invoked
;; as `(+ @errors-counter 10)`.
(send errors-counter + 10)
;; -> #<Agent@6a6287b2: 1>
@errors-counter
;; -> 11
send and send-off are largely similar. The difference is in how they are implemented. send uses a fixed-size thread pool so using blocking operations with it won’t yield good throughput. send-off uses a growing thread-pool so blocking operations is not a problem for it as long as there are resources available to the JVM to create and run all the threads.
Using Custom Executors With Agents
Agents can be used (and abused) for arbitrary code execution in a thread pool. Because the default thread pool Clojure maintains will not be a good fit for all use cases, Clojure 1.5 introduced a function that lets you control what thread pool (executor) is used by clojure.core/send: clojure.core/set-agent-send-executor!.
(import java.util.concurrent.Executors)
(set-agent-send-executor! (Executors/newFixedThreadPool 32))
;; clojure.core/send now will use the fixed size thread pool with 32 threads
The default thread pool size is number of available CPU cores + 2.
clojure.core/set-agent-send-off-executor! is a similar function that controls what thread pool clojure.core/send-off will use.
Finally, another new function in 1.5 is clojure.core/send-via which is like clojure.core/send but lets you specify an executor to be used on a case-by-case basis:
(import java.util.concurrent.Executors)
(def custom-pool (Executors/newFixedThreadPool 32))
;; just like clojure.core/send but will use custom-pool instead
;; of an internally maintained one
(send-via custom-pool stream-agent inc)
Agents and Error Handling
Functions that modify an agent’s state will not always return successfully in the real world. Sometimes they will fail. Failed agents will re-raise the exception that caused them to fail every time their state changed is attempted:
@errors-counter
;; -> 11
(send errors-counter / 0)
;; -> #<Agent@6a6287b2: 10>
(send errors-counter inc)
;; Evaluation aborted.
To access the exception that occured during the agent’s state mutation, use clojure.core/agent-error:
(send errors-counter / 0)
;; Evaluation aborted.
;; -> nil
(agent-error errors-counter)
;; -> #<ArithmeticException java.lang.ArithmeticException: Divide by zero>
It returns an exception. Agents can be restarted with clojure.core/restart-agent that takes an agent and a new initial value:
(restart-agent errors-counter 0)
;; -> 0
(send errors-counter + 10)
;; -> #<Agent@6a6287b2: 0>
@errors-counter
;; -> 10
If you’d prefer an agent to ignore exceptions instead of going into the failure mode, clojure.core/agent takes an option that controls this behavior: :error-mode. Because completely ignoring errors is rarely a good idea, when the error mode is set to :continue you must also pass an error handler function:
(def errors-counter (agent 0
:error-mode :continue
:error-handler (fn [failed-agent ^Exception exception]
(println (.getMessage exception)))))
;; -> #'user/errors-counter
(send errors-counter inc)
;; -> #<Agent@5620e147: 1>
(send errors-counter inc)
;; -> #<Agent@5620e147: 2>
(send errors-counter / 0)
;; output: "Divide by zero"
;; -> #<Agent@5620e147: 2>
(send errors-counter inc)
;; -> #<Agent@5620e147: 3>
@errors-counter
;; -> 3
The handler function takes two arguments: an agent and the exception that occured.
Agents are asynchronously updated references. They can be used for anything that does not require strict consistency for reads:
- Counters (e.g. message rates in event processing)
- Collections (e.g. recently processed events)
Agents can be used for offloading arbitrary computations to a thread pool, however, only starting with Clojure 1.5 they can provide the same flexiblity as JDK executors (thread pools).
Refs
Refs are the only coordinated reference type Clojure has. They help ensure that multiple identities can be modified concurrently within a transaction:
- Either all refs are modified or none are
- No race conditions between involved refs
- No possibility of deadlocks between involved refs
Refs provide ACI of ACID. Refs are backed by Clojure’s implementation of software transactional memory (STM).
To instantiate a ref, use the clojure.core/ref function:
(def account-a (ref 0))
;; ⇒ #'user/account-a
(def account-b (ref 0))
;; ⇒ #'user/account-b
Like atoms and agents covered earlier, to get the current value of a ref, use clojure.core/deref or the @ reader macro:
Refs are for coordinated concurrent operations and so it does not make much sense to use a single ref (in that case, an atom would be sufficient). Refs are modified in a transaction in the clojure.core/dosync body.
clojure.core/dosync starts a transaction, performs all modifications and commits changes. If a concurrently running transaction modifies a ref in the current transaction before the current transaction commits, the current transaction will be retried to make sure that the most recent value of the modified ref is used.
Refs are modified using clojure.core/alter which is very similar to clojure.core/swap! in the arguments it takes: a ref, a function that takes an old value and returns a new value of the ref, and any number of optional arguments to pass to the function.
In the following example, two refs are initialized at 1000, representing two bank accounts. Then 100 units are transferred from one account to the other, atomically:
(def account-a (ref 1000))
;; -> #'user/account-a
(def account-b (ref 1000))
;; -> #'user/account-b
(dosync
;; will be executed as (+ @account-a 100)
(alter account-a + 100)
;; will be executed as (- @account-b 100)
(alter account-b - 100))
;; -> 900
@account-a
;; -> 1100
@account-b
;; -> 900
With a high number of concurrently running transactions, retries overhead can become noticeable. Some modifications, however, can be applied in any order. Clojure’s STM implementation acknowledges this fact and provides an alternative way to modify refs: clojure.core/commute. commute must only be used for operations that commute in the mathematical sense: the order can be changed without affecting the result. For example, addition is commutative (1 + 10 produces the same result as 10 + 1) but substraction is not (1 − 10 does not equal 10 − 1).
clojure.core/commute has the same signature as clojure.core/alter.
Note that a change made to a ref by commute will never cause a transaction to retry. commute does not cause transaction conflicts.
Limitations of Refs
Software transactional memory is a powerful but highly specialized tool. Because transactions can be retried, you must only use pure functions with STM. I/O operations cannot be undone by the runtime and very often are not idempotent.
Structuring your application code as pure core and edge code that interacts with the user or other services (performing I/O operations and other side-effects) helps with this. In that case, the pure core can use STM without issues.
For example, in a Web or network server, incoming requests are the edge code: they do I/O. The pure core is then called to modify server state, do any calculations necessary, return a result that is returned back to the client by the edge code.
Unlike some other languages and runtimes (for example, Haskell), Clojure will not prevent you from doing I/O in transactions. It is left as a matter of discipline on the programmer’s part. It does provide a helper function, though: clojure.core/io! will raise an exception if there is an STM transaction running and has no effect otherwise.
First, an example with pure code:
(io!
;; pure code, clojure.core/io! has no effect
(reduce + (range 0 100)))
;; -> 4950
And an example that invokes functions that are guarded with clojure.core/io! in an STM transaction:
(defn render-results
"Prints results to the standard output"
[]
(io!
(println "Results:")
(comment ...)))
;; -> #'user/render-results
(dosync
(alter account-a + 100)
(alter account-b - 100)
(render-results))
;; throws java.lang.IllegalStateException, "I/O in transaction!"
Vars
Vars are the reference type you are already familiar with. You define them via the def special form:
(def url "http://en.wikipedia.org/wiki/Margarita")
Functions defined via defn are also stored in vars. Vars can be dynamically scoped. They have root bindings that are initially visible to all threads. When defining a var with def, you define a var that only has root binding, so its value will be the same no matter what thread you use it from:
(def url "http://en.wikipedia.org/wiki/Margarita")
;; -> #'user/url
(.start (Thread. (fn []
(println (format "url is %s" url)))))
;; outputs "url is http://en.wikipedia.org/wiki/Margarita"
;; -> nil
(.start (Thread. (fn []
(println (format "url is %s" url)))))
;; outputs "url is http://en.wikipedia.org/wiki/Margarita"
;; -> nil
Dynamic Scoping and Thread-local Bindings
To temporarily change var value, we need to make the var dynamic by adding :dynamic true to its metadata and then use clojure.core/binding:
(def ^:dynamic *url* "http://en.wikipedia.org/wiki/Margarita")
;; -> #'user/*url*
(println (format "*url* is now %s" *url*))
;; outputs "*url* is now http://en.wikipedia.org/wiki/Margarita"
(binding [*url* "http://en.wikipedia.org/wiki/Cointreau"]
(println (format "*url* is now %s" *url*)))
;; outputs "*url* is now http://en.wikipedia.org/wiki/Cointreau"
;; -> nil
Note that, by convention, vars which are supposed to or may be dynamically scoped are named with leading and trailing asterisks * (often referred to as “earmuffs”).
In the example above, binding temporarily changed the var’s current value to a different URL. But that happened only in the same thread as the var was originally defined in. What makes vars interesting from the concurrency point of view is that their bindings can be thread-local (yes, if you are familiar with thread-local variables in Java or Ruby, it is very similar and serves largely the same purpose). To demonstrate, let’s change the example to spin up 3 threads and alter the var’s value from them:
(def ^:dynamic *url* "http://en.wikipedia.org/wiki/Margarita")
;; -> #'user/*url*
(println (format "*url* is now %s" *url*))
;; outputs "*url* is now http://en.wikipedia.org/wiki/Margarita"
;; -> nil
(.start (Thread. (fn []
(binding [*url* "http://en.wikipedia.org/wiki/Cointreau"]
(println (format "*url* is now %s" *url*))))))
;; outputs "*url* is now http://en.wikipedia.org/wiki/Cointreau"
;; -> nil
(println (format "*url* is now %s" *url*))
;; outputs "*url* is now http://en.wikipedia.org/wiki/Margarita"
;; -> nil
As you can see, var scoping in different threads did not modify the var’s value in the thread it was originally defined in (its root binding). In real-world cases, for example, it means that a multi-threaded Web crawler can store some crawling state specific to a particular thread in a var and not modify its initial (global) value.
How to Alter Var Root
Sometimes, however, modifying the root binding is necessary. This is done via clojure.core/alter-var-root which takes a var (not its value) and a function that takes the old var value and returns a new one:
*url*
;; -> "http://en.wikipedia.org/wiki/Margarita"
(.start (Thread. (fn []
(alter-var-root (var user/*url*)
(fn [_] "http://en.wikipedia.org/wiki/Apéritif"))
(println (format "*url* is now %s" *url*)))))
;; outputs "*url* is now http://en.wikipedia.org/wiki/Apéritif"
;; -> nil
*url*
;; -> "http://en.wikipedia.org/wiki/Apéritif"
clojure.core/var is used to locate the var (user/url in our example executed in the REPL). Note that it finds the var itself (the reference, the “box”), not its value (what the var evalutes to).
In the example above the function we use to alter var root ignores the current value and simply returns a predefined string:
(fn [_] "http://en.wikipedia.org/wiki/Apéritif")
Such functions are common enough for clojure.core to provide a convenience higher-order function called clojure.core/constantly. It takes a value and returns a function that, when executed, ignores all its parameters and returns that value. So, the function above would be more idiomatically written as
*url*
;; ⇒ "http://en.wikipedia.org/wiki/Margarita"
(.start (Thread. (fn []
(alter-var-root (var user/*url*)
(constantly "http://en.wikipedia.org/wiki/Apéritif"))
(println (format "*url* is now %s" *url*)))))
;; outputs "*url* is now http://en.wikipedia.org/wiki/Apéritif"
;; ⇒ nil
*url*
;; ⇒ "http://en.wikipedia.org/wiki/Apéritif"
When is alter-var-root used in real world scenarios? Some Clojure data store and API clients stores active connection in a var, so initial connection requires root binding modification.
To summarize: vars can have dynamic scope. They have a root binding and can have thread-local bindings as well. As such, vars are good for storing pieces of program state that vary between threads but cannot be stored in a function local. alter-var-root is used to alter root binding of a var. It is done the functional way: by providing a function that takes the old var value and returns a new one.
To alter var root to a specific known value, use clojure.core/constantly.